Learning vocabulary on the command line
I like the idea of adding little bits of learning to my day that don’t take much effort once I’ve set them up. They’re not the most effective way to learn, but they certainly don’t hurt and every now and then you do get something worthwhile out of them.
One of the things I’ve set up recently is displaying random Chinese vocabulary items at the start of every command line session in Zsh.
The first iteration was very basic. I put a copy of CEDICT in my home directory. It’s then possible to get random lines from the dictionary with this command:
shuf -n 1 ~/cedict_1_0_ts_utf-8_mdbg.txtRunning that a few times gives you stuff like this:
轂 毂 [gu3] /hub of wheel/
連州 连州 [Lian2 zhou1] /Lianzhou city in Guangdong/
事業 事业 [shi4 ye4] /undertaking/project/activity/
察言觀色 察言观色 [cha2 yan2 guan1 se4] /observe sb's words and gestures/As you can see, you get all sorts of random vocabulary due to the breadth of the CEDICT dictionary. I don’t mind this, but you can easily use a custom vocabulary list with more specific content if you want more practical words to come up.
The other issue with having the entirety of CEDICT available is that there’s the chance of inappropriate vocab appearing at inopportune moments. I have this set up on my work computer and it can spit out things that are hard to explain to a colleague who’s looking at my screen at that moment (the best / worst one so far was “戀屍癖”). Sometimes I just explain what it is, and other times I use ctrl+l to get rid of it quickly!
It’s easy to alias that command and run it on every new session in ~/.zshrc:
alias suijici="shuf -n 1 ~/cedict_1_0_ts_utf-8_mdbg.txt"
suijiciHowever, the entries in CEDICT are consistently formatted and it seems a shame to waste that. I put together this regex that should match the four parts of a CEDICT entry (simplified, traditional, pinyin and definition):
^(.+)\s(.+)\s\[(.+)\]\s\/(.+)\/$We can then pipe the output of the shuf command through that expression using
awk (which ends up with a bad case of
leaning toothpick syndrome,
but oh well). I’ve used it to drop the simplified characters and reformat the
line:
awk '{ match($0, "^(.+)\\s(.+)\\s\\[(.+)]\\s\\/(.+)\\/\r$", a) }; { print a[1] " (" a[3] "): " a[4] }'(Note the addition of \r before $ in the regex to match the line return
included by shuf.)
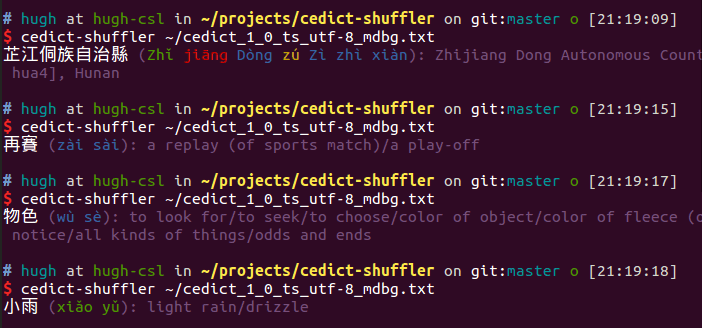
Now we get output like this:
窗簾 (chuang1 lian2): window curtainsIt’s better than before, but it’s also nice to make the Chinese stand out more than the pinyin or definition. That can be achieved with ANSI escape sequences in the print part of the awk command:
{ print "\x1b[93m" a[1] "\x1b[0m \x1b[35m(" a[3] ")\x1b[0m: \x1b[35m" a[4] }Then you get output with the different parts of the CEDICT entry in different colours. The final command looks like this:
shuf -n 1 ~/cedict_1_0_ts_utf-8_mdbg.txt | awk '{ match($0, "^(.+)\\s(.+)\\s\\[(.+)]\\s\\/(.+)\\/\r$", a) }; { print "\x1b[93m" a[1] "\x1b[0m \x1b[35m(" a[3] ")\x1b[0m: \x1b[35m" a[4] }'I could leave it there, but the pinyin tone numbers are too tempting. It’s
possible to convert those into tonemarks and colour-code them with regex. That
might be possible on the command line, but it would involve applying a list of
regex replaces to part of the output of awk or something, which I can’t think
how to achieve. Besides that it would be far from readable.
Instead, I’ve made a little program in Go that does this faster than the command line tools and in a much more readable way.
Here’s the source:
package main
import (
"bufio"
"bytes"
"fmt"
"golang.org/x/text/unicode/norm"
"math/rand"
"os"
"regexp"
"strconv"
"strings"
"time"
)
func main() {
cedictFile, err := os.Open(os.Args[1])
defer cedictFile.Close()
check(err)
entry := makeCedictEntry(randomLine(cedictFile))
fmt.Printf(
"%s \x1b[35m(\x1b[0m%s\x1b[35m): %s\n", entry.traditional,
entry.prettyPinyin(), entry.definition,
)
}
// Bail out on an error
func check(e error) {
if e != nil {
panic(e)
}
}
// Get a random line from a file with even distribution
func randomLine(file *os.File) (chosenLine string) {
scanner := bufio.NewScanner(file)
count := float64(0)
rand.Seed(time.Now().UnixNano())
for scanner.Scan() {
count++
if rand.Float64() <= (1 / count) {
chosenLine = scanner.Text()
}
}
return
}
// A CEDICT entry
type Entry struct {
simplified string
traditional string
pinyin string
definition string
}
// Convert entry's pinyin to tonemarks and apply ANSI colours
func (e *Entry) prettyPinyin() string {
syllables := strings.Split(e.pinyin, " ")
mark := toneMarker()
colour := toneColourer()
var buffer bytes.Buffer
for i, syllable := range syllables {
tone, letters := toneAndLetters(syllable)
marked := mark(tone, letters)
colouredAndMarked := colour(tone, marked)
buffer.WriteString(colouredAndMarked)
if i < len(syllables)-1 {
buffer.WriteString(" ")
}
}
return buffer.String()
}
// Make an Entry out of a CEDICT line string
func makeCedictEntry(entry string) Entry {
entryPattern := regexp.MustCompile(`^(\p{Han}+)\s(\p{Han}+)\s\[(.+)\]\s\/(.+)\/$`)
parts := entryPattern.FindStringSubmatch(entry)
if parts == nil || len(parts) != 5 {
panic("Failed to parse CEDICT line: " + entry)
}
return Entry{
traditional: parts[1],
simplified: parts[2],
pinyin: vsToUmlaut(parts[3]),
definition: parts[4],
}
}
// Replace "v" with "\u00fc" and "V" with "\u00dc"
func vsToUmlaut(pinyin string) string {
return strings.Replace(
strings.Replace(pinyin, "V:", "U\u0308", -1), "v:", "u\u0308", -1,
)
}
// Get pinyin tonemarking closure
func toneMarker() func(tone int, letters string) string {
toneMarks := [4]string{"\u0304", "\u0301", "\u030C", "\u0300"}
targets := [13]string{"A", "E", "I", "O", "U", "\u00dc", "iu", "a", "e", "i",
"o", "u", "\u00fc"}
toneMarker := func(tone int, letters string) string {
checkTone(tone)
if tone == 5 {
return letters
}
// Replace first found tonemark target vowel with tonemarked version
for i := 0; i < 13; i++ {
if strings.Index(letters, targets[i]) > -1 {
replaced := strings.Replace(letters, targets[i],
targets[i]+toneMarks[tone-1], 1)
return string(norm.NFC.Bytes([]byte(replaced)))
}
}
return letters
}
return toneMarker
}
// Wrap given string in ANSI output colours for MDBG tone
func toneColourer() func(tone int, syllable string) string {
colours := [5]string{"\x1b[31m", "\x1b[33m", "\x1b[32m", "\x1b[34m",
"\x1b[30m"}
end := "\x1b[0m"
toneColourer := func(tone int, syllable string) string {
checkTone(tone)
return fmt.Sprintf("%s%s%s", colours[tone-1], syllable, end)
}
return toneColourer
}
// Bail out if tone not in range 1-5
func checkTone(tone int) {
if tone < 1 || tone > 5 {
panic("Invalid tone: " + string(tone))
}
}
// Get the tone and plain letters of a pinyin syllable
func toneAndLetters(syllable string) (int, string) {
tone, err := strconv.Atoi(syllable[len(syllable)-1 : len(syllable)])
check(err)
checkTone(tone)
letters := syllable[:len(syllable)-1]
return tone, letters
}Not the most beautiful program in the world but it gets the job done: